



MultipleModelStatusNo Chinese content provided for translation.ModelType
Bringing significant technological innovation to the security industry
Based on the Guanlan Large Model Technology System
Hikvision will be focusing on large parameter volumes and large sample sizes.
Multimodal Large-scale Text and Image Model
Deeply integrated with embedded intelligent hardware
Introducing the Multimodal Large Model Search and Storage Product Series
—— Wensou NVR, Wensou CVR

Hikvision Wen搜 Storage Series
Leveraging Multimodal Large Models
Achieve natural language processing and video image integration
Cross-modal Information Retrieval Application
InputPlease provide the Chinese content you would like translated into American English.No Chinese content provided. Please provide the text to be translated.Please provide the Chinese content you would like translated into American English.No Chinese content provided for translation.、Please provide the Chinese content to be translated.No Chinese content provided.No Chinese content provided, please provide the text to be translated.Please provide the Chinese content to be translated.Unable to provide translation without the content. Please provide the Chinese text for translation.InstantlyNo Chinese content provided.Please provide the Chinese content you would like translated into American English.Sorry, there is no Chinese content provided to translate. Please provide the text you would like translated.No Chinese content provided.No Chinese content provided. Please provide the text to be translated.ImageLike
Our target search has become broader, more accurate, faster, and easier.
Revolutionizing Security Surveillance: No Longer Limited to Video Retrieval
Traditional time-space, alarm, and search methods
Significantly enhance the search efficiency for goals and events
Enhance Security Business Management with Increased Efficiency and Intelligence
01
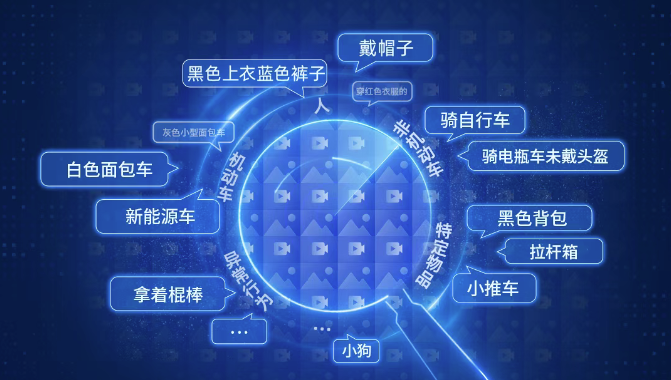
Sogou's Open Semantic Search: Search People, Cars, and Objects
Based on a multimodal large model, Wen Sou Storage's product has achieved open semantic search for massive view data, no longer limited to traditional video playback and fixed attribute searches.
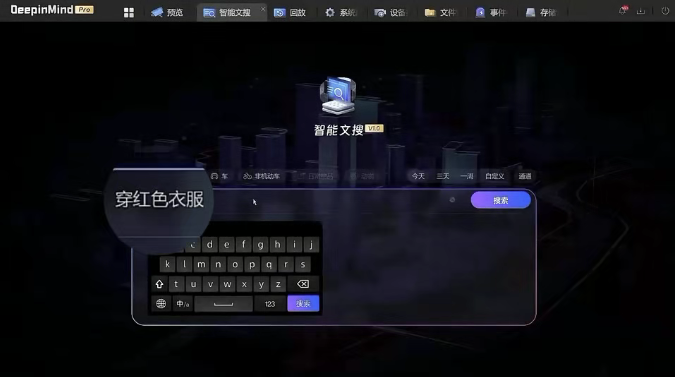
Enter a textual description (a sentence or a word, etc.) in the search box, such as "make a phone call," "white van," "riding an electric scooter without a helmet," "bicycle," "stroller," "small dog," and other open textual semantic descriptions, to search for relevant targets.
Our search capabilities are extensive, supporting frequent target searches in security scenarios such as for people, motor vehicles, and non-motor vehicles, as well as broad support for searches based on specific items and abnormal behaviors.
02
Sought After Text and Image Precise Matching
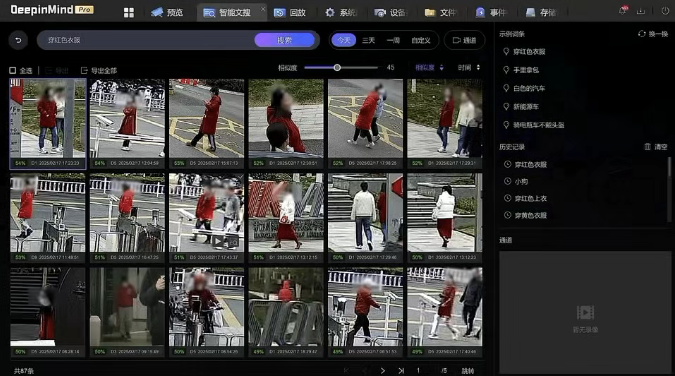
Utilizing multimodal large model technology, we extract features from images and search queries, aligning image features with critical semantic features in the search language to achieve high-precision search.
If you can understand textual descriptions like "wearing red clothes," "carrying a black backpack," "wearing a hat," "pulling a suitcase," and "carrying a stick," you can accurately search for related targets. For common targets, the hit rate can reach over 90% in the top 20 searches. (Data from the Hikvision Lab)
03
Sought Fast
Instant search results
Employing innovative technologies such as three-tier data caching, balanced sampling, and asynchronous loading, we achieve instantaneous display of text search results.
04
SearchEasy
Sleek operation, effortless search
In addition to manual text input for searches, the site now offers quick search options for finding people, motor vehicles, non-motor vehicles, pets, and common items, tailored to users' frequent scenarios. It also supports users in customizing their search phrases for simpler operations and enhanced convenience.

Based on the Guanlan Large Model technology system, we are advancing product innovation. The Wensou Storage series products leverage the Hikvision Guanlan Large Model technology system to bring about a transformation in intelligent applications. The Guanlan Large Model's multi-modal large model for images and text, built upon the foundation of large language models, undergoes continuous pre-training with multi-modal image and text data, acquiring visual perception and cognition capabilities. Thanks to the powerful perception and cross-task generalization abilities of the multi-modal large model, the entry barrier for visual intelligence business applications has been significantly reduced. The Wensou Storage series products represent a breakthrough in the application of multi-modal large model algorithms combined with embedded intelligent hardware. Through platform-oriented model design, large-to-small model distillation, cross-layer mixed precision quantization, and other large model deployment technologies, along with innovative designs of embedded intelligent hardware, we have achieved the implementation of multi-modal large models on lightweight embedded hardware platforms. This enables the multi-modal large model technology to achieve universal application, allowing more industries and users to enjoy the intelligence and convenience brought by large models.
